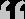从2022年年底开始大火,ChatGPT的一举一动都备受关注,它真的会改变我们认知世界的方式吗?会深入改变人类社会吗?
chatgpt中文版 http://www.shikelang.cc
在思考这些问题之前,我们有必要了解并认识ChatGPT。而在图灵文化公司开创总编,联合开创人刘江看来,计算机科学家斯蒂芬·沃尔弗拉姆所著的《这就是ChatGPT》,是能够讲透GPT的原理和未来的佳作。
刘江 | 撰文
1
从2022年11月发布到现在差不多半年的时间,ChatGPT所引发的关注、产生的影响,可能已超出了信息技术历史上几近所有热门。它的用户数2天到达100万,2个月到达1亿,打破TikTok之前的纪录。而在2023年5月iOS App发布后,也毫无悬念地登顶苹果利用商店总排行榜。许多人平生第一次接触到如此高智能、知错能改的对话系统。撰写文章、虽然很多时候会非常自信、“一本正经的胡说八道”,乃至简单的加减法也算不对,但你提示它错了,或让它一步步地来,它会很灵地真的变得非常靠谱,有条不紊地列出做事情的步骤,然后得出正确答案。有些复杂的任务,你正等着看它笑话呢,它却不紧不慢地给你言之成理的回答,让你大吃一惊。本来不看好乃至在2019年微软投资OpenAI的决策中投了反对票的盖茨,现在将ChatGPT与PC、互联网等等量齐观,黄仁勋称之为iPhone时刻,OpenAI的Sam Altman比作印刷机,Google CEO Sundar Pichai说是火和电,与腾讯马化腾“几千载难逢”的观点所见略同,总之都是开启了新时期。阿里巴巴张勇的建议是:“所有行业、利用、软件、服务,都值得基于大模型能力重做一遍”。以马斯克为代表的很多专家更是由于ChatGPT的突破性能力可能对人类产生要挟,呼吁应当暂停强大AI模型的开发。
刚刚结束的2023智源大会上,Sam Altman很自信地说AGI极可能在十年以内到来,需要全球合作解决由此带来的各种问题。而由于共同推动深度学习从边沿到舞台中央而取得图灵奖的三位科学家,意见却明显区别:Yann LeCun明确表示GPT代表的自回归大模型存在本质缺点,需要围绕世界模型另寻新路,所以他对AI的要挟其实不担心。
在另外一名讲者插播视频里出现的Yoshua Bengio虽然也不认同单靠GPT线路就可以通向AGI(他看好贝叶斯推理与神经网络的结合),但承认大模型存在巨大潜力,从第一性原理来看也没有明显的天花板,因此他在呼吁暂停AI开发的公然信上签了字。
压轴演讲的Geoffrey Hinton明显同意自己的弟子Ilya Sutskever大模型能学习到真实世界紧缩表示的观点,他意想到具有反向传播(通俗地理解就是内置知错能改机制)而且能轻易扩大范围的人工神经网络,智能可能会很快超过人类,因此他也加入到呼吁AI风险的队伍中来。
ChatGPT代表的人工神经网络的逆袭之旅,在全部科技史上也算得上跌宕起伏。它曾在流派众多的人工智能界内部屡受轻视和打击。不止一名天才先驱以悲剧结束一生:1943年Walter Pitts与Warren McCulloh提出神经网络数学表示时才20岁,他中学都没有念完,后来由于与导师维纳失和,脱离学术界,因饮酒过度46岁即英年早逝;1958年30岁时通过感知机实际实现了神经网络的Frank Rosenblatt,43岁生日溺水身亡;反向传播的主要提出者David Rumelhart则是50多岁正值盛年罹患罕见的不治之症,1998年开始逐步失智,2011年与病魔斗争十多年后离世。一些顶级会议和明斯基这样的学术伟人都曾绝不客气地反对乃至排挤神经网络,逼得Hinton等人不能不前后采取“关联记忆”、“并行散布式处理”、“卷积网络”、“深度学习”等更中性或晦涩的术语为自己赢得一隅生存空间。Hinton自己从1970年代开始,坚守冷门方向几十年,从英国到美国最后立足曾的学术边境加拿大,在资金支持匮乏的情况下努力建立起一个人数不多但精英辈出的学派。直到2012年他的博士生Ilya Sutskever等在ImageNet比赛中用新方法一飞冲天,深度学习开始成为AI的显学,并广泛利用于各个产业。2020年,他又在OpenAI带队,通过千亿参数的GPT⑶开启了大模型时期。2015年30岁的Sam Altman和28岁的Greg Brockman与马斯克联手,召集了30岁的Ilya Sutskever等多位AI顶级人材,共同创建OpenAI,希望在谷歌、Facebook等诸多巨头以外,建立中立的AI前沿科研气力,并雄心勃勃地把人类水平的人工智能作为自己的目标。那时候,媒体基本上报导基本上都是以马斯克支持成立了一家非营利AI机构为标题,并没有多少人看好OpenAI。乃至Ilya Sutskever这样的灵魂人物,加入前也经过了一番思想斗争。前三年,他们在强化学习、机器人、多智能体、AI安全等方面多线出击,也的确没有获得特别有说服力的成果。以致于主要援助人马斯克对进展不满意,动念要来直接收理,被理事会谢绝后,选择了完全离开。2019年3月,Sam Altman开始担负OpenAI的CEO,并在几个月内完成了组建商业公司、取得微软10亿美元投资等,为后续发展做好了准备。而科研方面,2014年Olin工学院本科毕业两年后加入OpenAI的Alec Radford开始发力,作为主要作者,他在Ilya Sutskever等的指点下,连续完成了PPO(2017)、GPT⑴(2018)、GPT⑵(2019)、Jukebox(2020)、ImageGPT(2020)、CLIP(2021)、Whisper(2022)等多项首创性工作。特别是2017年情感神经元的工作,首创了“预测下一个字符”的极简架构结合大模型、大算力、大数据的技术线路,对后续GPT产生了关键影响。从下图1可以清晰地看到,GPT⑴论文发表以后,OpenAI这类成心为之的更加简单的decoder-only架构(准确地讲是带自回归的encoder-decoder)并没有得到太多关注,风头都被几个月以后谷歌的BERT(encoder-only架构,准确地讲是encoder-非自回归的decoder)抢去了。出现了一系列xxBERT类的很有影响的工作。图1 大模型进化树,出自Amazon杨靖锋等2023年4月的论文“Harnessing the Power of LLMs in Practice”
即便到今天,后者的援用数累计已超过6.8万,比GPT⑴的不到6000依然高了一个数量级。两篇论文技术线路区别,不管是学术界或者工业界,几近所有人当时都选择了BERT阵营。
2019年2月发布的GPT⑵将最大参数范围提升到15亿级别,同时使用了更大范围、更高质量和更多样的数据,模型开始展现很强的通用能力。当时令GPT⑵登上技术社区头条的,还不是研究本身(直到今天论文援用数也是6000出头,远不如BERT),而是OpenAI出于安全斟酌,最开始只开源了最小的3.45亿参数模型,引发轩然大波。社区对OpenAI不Open的印象,始自这里。这前后OpenAI还做了范围对语言模型能力影响的研究,提出了“范围定律”(Scaling Law),肯定了全部组织的主要方向:大模型。为此,将强化学习、机器人等其他方向都砍掉了。难能宝贵的是,大部份核心研发人员选择了留下,改变自己的研究方向,放弃小我,集中气力做大事,很多人转而做工程和数据等工作,或围绕大模型重新定位自己的研究方向(比如强化学习就在GPT 3.5和以后的演进中发挥了重大作用)。这类组织上的灵活性,也是OpenAI能成功的重要因素。2020年GPT⑶横空出世,NLP小圈子里的一些有识之士开始意想到OpenAI技术线路的巨大潜力。在中国,北京智源人工智能研究院联合清华大学等高校推出了GLM、CPM等模型,并积极在国内学术界推广大模型理念。从图1看到,2021年以后,GPT线路已完全占据上风,而BERT这一“物种”的进化树几近停止了。2020年年底,OpenAI的两位副总Dario和Daniela Amodei兄妹带领多位GPT⑶和安全团队的同事离开,创办了Anthropic。Dario Amodei在OpenAI的地位非同一般,他是Ilya Sutskever以外,技术线路图的另外一个制定者,也是GPT⑵和GPT⑶项目和安全方向的总负责人。而随他离开的,有GPT⑶和范围定律论文的多位核心。一年后,Anthropic发表论文“A General Language Assistant as a Laboratory for Alignment” ,开始用聊天助手研究对齐问题。尔后逐步演化为Claude这个智能聊天产品。2022年6月,“Emergent Abilities of Large Language Models”论文发布,一作是从达特茅斯学院本科毕业才两年的谷歌研究员Jason Wei(今年2月他也在谷歌精英跳槽潮中去了OpenAI)。文中研究了大模型的出现能力,这类能力在小模型中不存在,只有模型范围扩大到一定量级才会出现。也就是我们熟习的“量变会致使质变”。到11月中旬,本来一直在研发GPT⑷的OpenAI员工收到管理层的指令,所有工作暂停,全力推出一款聊天工具,缘由是有竞争。两周后,ChatGPT诞生。这以后的事情已载入史册。业界推测,OpenAI管理层应当是得到了Anthropic Claude的进展情况,意想到这一产品的巨大潜力,决定先下手为强。这展现出核心人员超强的战略判断力。要知道,即便是ChatGPT的核心研发人员也不知道为何产品推出后会这么火(“我爸妈终究知道我在干甚么了”),他们在自己试用时完全没有冷艳的感觉。2023年3月,在长达半年的“评估、对抗性测试和对模型和系统级减缓措施的迭代改进”以后,GPT⑷发布。微软研究院对其内部版本(能力超越公然发布的线上版本)研究的结论是:“在所有这些任务中,GPT⑷的表现与人类水平惊人的接近……鉴于GPT⑷的广度和深度,我们认为它可以公道地被视为通用人工智能(AGI)系统初期(但依然不完全)的版本。”尔后,国内外的企业和科研机构纷纭跟进,几近每周都有一个乃至多个新模型推出,但综合能力上OpenAI依然一骑绝尘,唯一可以与之对抗的,是Anthropic。很多人会问,为何中国没有产生ChatGPT?其实正确的问题(prompt)应当是:为何全球只有OpenAI能做出ChatGPT?他们成功的缘由是甚么?对此的思考,到今天仍成心义。2
他虽然其实不是马斯克那种大众层面家喻户晓的科技名人,但在科技极客小圈子里确是如雷灌耳的,被称为“在世的最聪明的人”。谷歌的开创人之一Sergey Brin大学期间曾慕名到Wolfram的公司实习。而搜狗和百川智能开创人王小川更是他出名的铁杆粉丝,“带着崇敬和狂热的心……关注和追随多年”。Wolfram小时候是出名的神童。由于不屑于看学校推荐的“蠢书”,而且算术不好,也不愿意刷已被人解答过的题,一开始老师们还以为这孩子不行。结果人家13岁就自己写了几本物理书,其中之一位为《亚原籽粒子物理》。15岁在Australian Journal of Physics发表了一篇正儿八经的高能物理论文“Hadronic Electrons?”,提出了一种新情势的高能电子-强子耦合。这篇论文还有5次援用。在英国的伊顿公学、牛津大学等名校Wolfram都是晃了几年,也不如何上课,他讨厌已被人解决的问题,结果没毕业就跑了,最后20岁在加州理工学院直接拿了博士,导师是大名鼎鼎的费曼。1981年Wolfram荣获第一届麦克阿瑟天才奖,是最年轻的获奖者。同一批都是各学科的大家,包括1992年诺贝尔文学奖得主沃尔科特。他很快对纯物理失去了兴趣。1983年转到普林斯顿高等研究院,开始研究元胞自动机,希望找到更多自然和社会现象的底层规律。这一转型产生了巨大影响。他成为复杂系统这一学科的首创者之一,有人认为他做出了诺贝尔奖级的工作。20多岁的他也的确与多位诺贝尔奖得主盖尔曼、菲利普·安德森(正是他1972年发表文章“More is Different”提出了出现这一概念)等一起参与了圣塔菲研究所的初期工作,并在UIUC创建复杂系统研究中心。他还创办了学术期刊Complex Systems。为了更方便地做元胞自动机相关的计算机实验,他开发了数学软件Mathematica(这个名字或者他的好友乔布斯取的),又进而创办软件公司Wolfram Research,转身为一名成功的企业家。Mathematica软件的强大,大家可以从本书后面对ChatGPT解读时高度抽象和清晰的语法中直观地感遭到。说实话,这让我动了想认真学一下这一软件和相关技术的动机。1991年,Wolfram又返回研究状态,开始昼伏夜出,每天深夜埋头做实验、写作长达十年,出版了1000多页的巨著A New Kind of Science。书中的主要观点是:万事皆计算,宇宙中各种复杂现象,包括人产生的或者自然中自发的,都可以用一些规则简单的计算摹拟。Amazon上书评的说法可能更好懂:“伽利略曾宣称自然界是用数学的语言书写的,但Wolfram认为自然界是用编程语言(而且是非常简单的编程语言)书写的。”而且这些现象或系统,比如人类大脑的工作和蔼象系统的演变,在计算方面是等效的,具有相同的复杂度,这称为“计算等价原理”。书很畅销,由于语言很通俗,又有近千幅图片,但学术界特别是物理老同行也有很多批评。主要集中在书中的理论其实不原创(图灵关于计算复杂性的工作,康威的生命游戏等都与此类似),而且缺少数学严谨性,因此很多结论很难经得住检验(比如自然选择不是生物复杂性的根本缘由,美国理论计算机科学家Scott Aaronson也指出Wolfram的方法没法解释量子计算中非常核心的贝尔测试的结果)。而Wolfram回应批评的方式是推出Wolfram|Alpha知识计算引擎,被很多人认为是第一个真正实用的人工智能技术,结合知识和算法,实现了用户采取自然语言发出命令,系统直接返回答案。全球的用户可以通过网页、Siri、Alexa包括ChatGPT插件来使用这一强大的系统。如果我们拿ChatGPT代表的神经网络来看Wolfram的理论,就会发现一种暗合关系:GPT底层的自回归架构,与很多机器学习模型相比,的确可以归类为“规则简单的计算”,而其能力也是通过量变积累之下出现出来的。Wolfram常常为好莱坞的科幻电影做技术支持,用Mathematica和Wolfram编程语言生成一些逼真的效果,比较著名的包括《星际穿越》里的黑洞引力透镜效应,和《降临》里掌握了以后能够超出时空的奇异外星人语言,都极富想象力。他当年终究离开学术界,与普林斯顿同事不和有关。老师费曼写信劝他:“你不会理解普通人的想法的,他们对你来讲只是傻瓜。”3
像Stephen Wolfram这样的大神能动手为广大读者关注度极高的主题写一本通俗读物,这本身就是一个奇迹。他40年前从纯物理转向复杂系统,就是想解决人类智能等现象的第一性原理,有很深的积累。由于他交游广泛,与Geffrey Hinton、Ilya Sutskever、Dario Amodei等关键人物都有交换,也有第一手资料,保证了技术的准确性。难怪本书出版后,OpenAI的CEO称之为“ChatGPT原理的最好解释”。全书分两部份,篇幅很小,但是关于ChatGPT最重要的点都讲到了,而且讲得通俗透彻。比如,GPT技术线路的一大核心理念,是用最简单的自回归生成架构,来解决无监督学习问题,也就是利用原始的数据无需人特地标注,然后从中学习数据中对世界的映照。其中自回归生成架构,就是书中讲得非常通俗的“只是一次添加一个词”。这里特别要注意的是,选择这类架构的目的其实不是为了做生成任务,而是为了理解或学习,是为了实现模型的通用能力。在2020年之前乃至以后的几年里,业界很多专业人士都想固然地以为GPT是弄生成任务的而选择了疏忽。却不知GPT⑴论文的标题就是“通过生成式预训练改进语言理解”。再比如,对没有太多技术背景或机器学习背景的读者来讲,了解人工智能最新动态时可能遇到的直接困难,是听不懂老出现的基本概念“模型”、“参数(在神经网络中就是权重)”是甚么意思,而这些概念其实不是那末容易讲清楚。本书中,大神作者非常贴心肠用直观的例子(函数和旋钮)做了解释。(参见“甚么是模型”一节)而关于神经网络的几节内容图文并茂,相信对各类读者更深入地理解神经网络及其训练进程的本质,和损失函数、梯度降落等概念都很有帮助。作者在讲授中也没有忽视思想性,比以下面的段落很好地介绍了深度学习的意义:“深度学习”在 2012 年左右的重大突破与以下发现有关:与权重相对较少时相比,在触及许多权重时,进行最小化 (最少近似)可能会更容易。
换句话说,有时候用神经网络解决复杂问题比解决简单问题更容易——这仿佛有些违背直觉。大致缘由在于,当有很多“权重变量”时,高维空间中有“很多区别的方向”可以引导我们到达最小值;而当变量较少时,很容易堕入局部最小值的“山湖”,没法找到“出去的方向”。
在神经网络的初期发展阶段,人们偏向于认为应当“让神经网络做 尽量少的事”。例如,在将语音转换为文本时,人们认为应当先 分析语音的音频,再将其分解为音素,等等。但是后来发现,(至 少对“类人任务”)最好的方法通常是尝试训练神经网络来“解 决端到真个问题”,让它自己“发现”必要的中间特点、编码等。
掌握这些概念的why,都有益于理解GPT的大背景。嵌入这个概念不管对从事大模型研发的算法研究者,基于大模型利用开发的程序员,或者想深入了解GPT的普通读者,都是相当重要的,也是“ ChatGPT 的中心思想”,但相对照较抽象,不是特别容易理解。本书“‘嵌入’的概念”一节是我见过的对这一概念最好的解释,通过图、代码和文字解读三种方式,相信大家都能掌握。固然,后文中“意义空间和语义运动定律”一节还有多张彩图,可以进一步深化这一概念。本节最后还介绍了常见词标记(token),并举了几个直观的英文例子。接下来对ChatGPT工作原理和训练进程的介绍也是通俗而不失严谨。对Transformer这个比较复杂的技术讲得非常细致,而且也照实告知了目前理论上并没有弄清楚为何这样就有效果。第一部份最后扫尾,结合作者的计算不可约理论,将ChatGPT的理解上升到一个高度,与Illya Sutskever在多个访谈里强调的GPT的大思路是通过生成来获得世界模型的紧缩表示异曲同工。产生“成心义的人类语言”需要甚么?过去,我们可能认为人类大脑必不可少。但现在我们知道,ChatGPT 的神经网络也能够做得非常出色。……我强烈怀疑 ChatGPT 的成功暗示了一个重要的“科学”事实:成心义的人类语言实际上比我们所知道的更加结构化、更加简单,终究可能以相当简单的规则来描写如何组织这样的语言。
语言是严肃思考、决策和沟通的工具,相比感知、行动,从孩子的获得前后和难易程度来看,应当是智能中最难的任务。但ChatGPT极可能已攻破了其中的密码,正如Wolfram说的“”。这确切预示着未来我们通过计算语言或其他表示方式,有可能进一步大幅提升整体智能水平。由此推广开来,人工智能的进展,有可能在各学科产生类似的效应:原来之前认为很难的课题,其实换个角度其实不是那末难的。加上GPT这类通用智能助手的加持,“一些任务从基本不可能变成了基本可行”,终究使全人类的科技水平到达新高度。本书的第二部份是ChatGPT与Wolfram|Alpha 系统对照与结合的介绍,有较多实例。如果说GPT这类通用智能更像人类的话,大部份人类确切是天生不善于精确计算和思考的,未来通用模型与专用模型的结合,应当也是前景广阔的方向。稍有遗憾的是,本书重点只讲了ChatGPT的预训练部份,而没有过量触及后面也很重要的几个微调步骤:监督微调(SFT)、嘉奖建模和强化学习。这方面比较不错的学习资料是2023年5月OpenAI开创成员、前Tesla AI负责人Andrej Karpathy在微软Build大会上的演讲“State of GPT”。关于AI能力的上限,他认为,根据“计算等价原理”,ChatGPT这类通用人工智能的出现证明了“(人类)本质上没有任何特别的东西——事实上,在计算方面,我们与自然中许多系统乃至是简单程序基本上是等价的”。因此,曾需要人类努力完成的事情,会逐步自动化,终究能通过技术不要钱完成。很多人认为是人类独有的创造力或原创力、情感、判断力等,AI应当也能够具有。终究,AI也会逐渐发展出自己的世界。这是一种新的生态,可能有自己的宪章,人类需要适应,与之共存共荣。根据“计算不可约性原理”(即“总有一些计算是没有捷径来加速或自动化的”,作者认为这是思考AI未来的核心),复杂系统中总是存在无穷的“计算可约区”,这正是人类历史上能不断出现科学创新、发明和发现的空间。所以,人类会不断向前沿进发,而且永久有前沿可以探索。同时,“计算不可约性原理”也决定了,人类、AI、自然界和社会等各种计算系统具有根本的不可预测性,始终存在“收获欣喜的可能”。人类宝贵的,是有内在驱动力和内在体验,能够内在地定义目标或意义,从而终究定义未来。最高效的方式是发掘新的可能性,定义对自己有价值的东西。
从现在的回答问题转向学会如何提出问题,和如何肯定哪些问题值得提出。也就是从知识履行转向知识战略。
知识广度和思惟清晰度将很重要。
直接学习所有详细的知识已变得没必要要了:我们可以在更高的层次上学习和工作,抽象掉许多具体的细节。“整合”,而不是专业化。尽量广泛、深入地思考,尽量多地调用知识和范式。
学会使用工具来做事。过去我们更倚重逻辑和数学,以后要特别注意利用计算范式,并应用与计算直接相关的思惟方式。
本书已在赛先生书店上架,欢迎点击图片租赁
ChatGPT是OpenAI开发的人工智能聊天机器人程序,于2022年11月推出,能够自动生成一些表面上看起来像人类写出的文字的东西,是一件很利害且出乎大家意料的事。那末,它是怎么做到的呢?又是为啥能做到的呢?本书会大致介绍ChatGPT的内部机理,然后探讨一下为何它能很好地生成我们认为是成心义的文本。
本书合适想了解ChatGPT的所有人浏览。
tk账号购买:https://www.tiktokfensi.com/