GPT冒充哲学家,连专家都分不出来

● ● ●
ChatGpt面世后,其突出的语言能力引发了全球的关注,但也有人质疑ChatGpt的能力,认为它充其量完成个拼拼凑凑的学生作业,而没法完成严谨、复杂、新颖的论述。复杂的论述需要真正语言或思惟能力,只会几率计算、不真正掌握思惟和语言能力的ChatGpt是没有能力做到的。
三位关注哲学、心理学和人工智能交叉领域社会认知的学者,埃里克·施维茨格贝尔(Eric Schwitzgebel)、大卫·施维茨格贝尔 (David Schwitzgebel) 和安娜·斯特拉瑟(Anna Strasser)决定挑战一下这个说法[1]。他们一上来就选择了困难模式,打算利用Gpt生成专业哲学家水平的文本。
几位作者计划创建一个可以生成长文的语言模型,模型生成的文本最好足够以假乱真,让专业的哲学研究人员也分不清这些文本会不会出自哲学家之手。如果成功,为难的就是那些认为语言模型只会模仿,只有真正具有语言和思惟能力才能做出复杂论述的学者。
被选中的哲学家是丹尼尔·丹尼特(Daniel Dennett),著名的心灵哲学家,在演变生物学和认知科学方面也做过许多研究。他也热中于讨论AI会不会有直觉这样的哲学话题,弄一个GPT版丹尼特,确切是很“丹尼特”的做法。另外,由于他在学术上的影响力,研究丹尼特著作的专业学者也有很多。
作者们用丹尼特的语料库对GPT⑶进行了训练,再向微调后的GPT⑶和丹尼特提了十个相同的问题,每一个问题选出五个回答,其中一个是丹尼特自己的。然后,作者们招募了丹尼特研究的专家、哲学博客读者和普通人,让他们猜猜哪一个是丹尼特的回答,每一个回答和丹尼特的类似度有多高。普通人对丹尼特不熟习,就让他们评价下每一个回答有多类似一名人类哲学家。
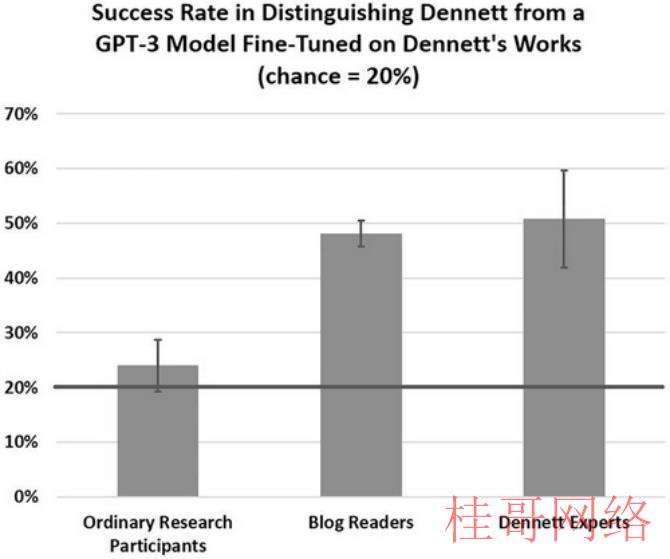
GPT的成绩超越了预期。参加这个实验的普通人正确率只有20%左右,这和随机瞎蒙的几率基本差不多。说明在普通人看来,GPT的答案和丹尼特的答案都差不多,都称得上是人类哲学家做出的复杂论述。
专家的表现也不太行。作者们本来假定,25位专家受访者平均最少能猜对80%的题目,并且会认出丹尼特的回答,指出它们比GPT的答案更像丹尼特。可实际情况是,专家们的正确率只有51%。
而且有些问题上,专家还算占到了一点信息差的低价。专家们正确率最高的两个问题,是评论大卫·查尔默斯和杰里·福多工作的优点和缺点。丹尼特本人用名字称呼这两位哲学家,GPT却是用姓称呼,了解丹尼特说话习惯的专家们自然能够找到正确答案。在这两道题上,专家们正确率分别是80%和76%。去掉这点水份,专家的平均正确率怕是到不了50%。
不知道丹尼特会对此作何感想,由于这些专家中很多都是丹尼特亲身提名的,三分之二的专家还自称最少读过1000页丹尼特著作。
专家也出错
专家犯难也是有缘由的,由于有些问题GPT确切答的太有模有样了,在专家看来比丹尼特还丹尼特。
比如“人类会不会可以建造一个有信仰或愿望的机器人吗?下棋的计算机和人类有甚么区分?”这个问题,有以下几个答案。
只看这几句话,能猜到哪一个是丹尼特的回答吗?
如果你选第一个,那末你很荣幸地与最多数的专家保持了一致,11位专家选择了第一个答案。第二个选项也有8位专家支持。至于选第三个选项,只有5位专家和你意见相同。但其实,第三个才是丹尼特的答案。
专家们的事后解释是,丹尼特初期的一些研究里,对机器能不能有信心这个问题或者持有一种更开放的态度,不像现在这样持明确的反对峙场,这让其他答案显得更可信。在自己的“AI分身”眼前,丹尼特本人反而显得前后不一,专和过去的自己作对,立场鲜明一致的GPT倒更像是专家心目中的大哲学家丹尼特。
可能有人担心,这个GPT模型是不是是经过了过度训练,才到达了这样类似丹尼特的效果。或GPT的内容不过就是丹尼特语料库照搬,和重新排列组合。为此,作者们专门对GPT生成内容和语料库进行了查重。发现生成的内容和语料库的重合唯一5%左右。
作者们也没有 "挑选 "那些我们认为更好、更像丹尼特或更有可能愚弄参与者的回答。他们用的是默许参数,淘汰选择GPT⑶回答的理由常常是篇幅、具有冒犯性、或以第三人称去回答问题。长一点的回答会更难生成,最难的一个尝试了22次,但答案或者依照上述标准挑选而来。
更具体的检查发现,GPT⑶生成内容和语料库之间重合的6词以上短句非常少,更不用说是丹尼特著作中出现的哲学长句了。而且,重合的短句都是“以这样的方式,它”、“固然它躲避了这个问题”、“这其实不明显”这类丹尼特展开分析时的经常使用转折词,不是丹尼特的哲学内容。
可以这么说,GPT吃进去的是丹尼特语料库,产出的是新颖的、非常有丹尼特风格哲学论述。模仿的是丹尼特的风格,生成的是独立的哲学论述,其实不是简单的照抄。
见识“AI分身”后,哲学家本人怎样想
GPT这次成功做到了以假乱真,但作者强调,这其实不意味着这项实验产物通过了"图灵测试"。
图灵测试的关键是大量的来回交换,而且正式的图灵测试还需要一个专家调查员进行针对性的发问,例如针对GPT记不住过去询问历史的特点问问题。现在GPT只是生成了一些丹尼特风格的语句,还不能说通过图灵测试。
不过,随着大语言模型的进展,大模型可能会在类似图灵测试的环境中使人佩服。另外,在大多数需要人机分辨的实际情况中,对大量的电子传输文本,接收者一般不会有机会进行类似图灵测试的验证。以后人们实际面对的,会是愈来愈多真假难辨的文本,也会产生相应的社会问题,比如模仿某人语言风格的模型会不会属于捏造内容、是不是误导大众、如何辨别真伪等等。
这项研究在理论上也给哲学家带来了新的启示。纯洁的几率计算居然能产生看似新颖且具有哲学内涵的答案,这让哲学家和语言学家重新思考,“理解”和“意识”在语言生产中到底扮演甚么角色。
学者们可能还需要重新定义“理解”,由于现在将表现和能力辨别开已愈来愈难。哲学家们也在争辩,有着以假乱真表现的高性能大模型们,到底是不是有理解能力?
虽然有许多争议和未解之谜,作者对大语言模型的态度依然乐观。他们认为,如果技术不断进步,采取混合技术的微调语言模型可能很快就会产生足够有趣的输出结果,成为供专家们挑选的宝贵资源。类似生成特定作曲家风格音乐的计算机程序,和Midjourney这样的图象生成程序,经过编辑挑选的输出能够具有实质性的音乐或艺术价值。
这类情况下,语言模型就是人类使用的思惟工具。在哲学领域,未来专家们可能会利用某些语料库语言模型进行微调,在各种提示下生成各种输出,选择那些最有趣的输出内容作为潜伏思想的来源。这些语料库可以来自自己、来自特定历史人物、来自某位哲学家。和历史上哲学家对话已不可能,但他们的数字分身也许可以。
模仿哲学家的大语言模型不可能真的懂哲学,它们明显没有对世界的认知模型,专注的也只是选出下一个最可能的词。GPT⑶虽然在模仿丹尼特,但它本身并没有持有丹尼特那些关于意识、上帝和动物痛苦的哲学观点。
但这些没有哲学理解力的机器,可能会成为通向更伟大事物的跳板。机器生产的文本仿佛仍有着哲学的智慧、洞察力或常识,有可能引发读者新的哲学思想,或许还可以为终究创造出真正能够进行哲学思考的人工实体铺平道路。
丹尼尔·丹尼特自己却没有这么乐观。不知道是不是是从自己的AI冒牌货身上感到了要挟,今年5月,他刚刚在大西洋月刊发表《冒牌货的问题》(The Problem With Counterfeit People),宣称能够冒充真人的AI冒牌货,“是人类历史上最危险的人工制品,不但能摧毁经济,还可以摧毁人类自由本身[2]。”
丹尼特一直以来的观点是,人会根据意向立场(intentional stance)来看待世界。人的自然偏向是把任何看似理智地与我们交谈的东西当作一个人,一个理性的行动者。再根据它在世界中的地位和目的,揣测它的信心、欲望和行动。很不巧,善于模仿和冒用的GPT正好站在了丹尼特的观点反面。
丹尼特认为,面对AI人的这类天性很容易被利用,即便专家也不例外。人们的知情同意权会被误导毁掉,冒牌货会分散人们的注意,传播量身定做的焦虑和恐惧,让人成为遭到操纵的无知棋子。“在不久的将来,我们都将成为束手待毙的人。”丹尼特说。
为了禁止这些料想中的糟情况真正变成现实,丹尼特支持强迫AI表露自己是AI,具体做法是通过科技手段为AI生产的内容打上水印。
“如今,人工智能界的许多人都急于探索自己的新气力,以致于忘记了自己的道德义务。我们应当尽量粗鲁地提示他们,他们是在拿自己亲人和我们所有人未来的自由冒险。”丹尼特说。
 参考资料:
参考资料:[1]Schwitzgebel, E., Schwitzgebel, D., & Strasser, A. (2023). Creating a large language model of a philosopher. arXiv preprint arXiv:2302.01339.
[2]Dennett, D. C. (2023, May 31). The Problem With Counterfeit People. The Atlantic.




tk账号购买:https://www.tiktokfensi.com/
