近期发表在《神经外科杂志》上的一项分析评估了ChatGPT (OpenAI) 在替换神经外科板式问题上的表现,发现自然语言处理 (NLP) 算法能够显著优于医学生,并且仅略低于目前正在学习自我评估神经外科(SANS) 委员会考试的住院医生的表现。鉴于神经外科中的机器学习已迅速成为人们非常感兴趣的话题,作者William Mack(美国洛杉矶南加州大学)及其同事着手评估人工智能(AI)模型在神经外科考试中的表现。
近期发表在《神经外科杂志》上的一项分析评估了ChatGPT (OpenAI) 在替换神经外科板式问题上的表现,发现自然语言处理 (NLP) 算法能够显著优于医学生,并且仅略低于目前正在学习自我评估神经外科(SANS) 委员会考试的住院医生的表现。鉴于神经外科中的机器学习已迅速成为人们非常感兴趣的话题,作者William Mack(美国洛杉矶南加州大学)及其同事着手评估人工智能(AI)模型在神经外科考试中的表现。研究方法:
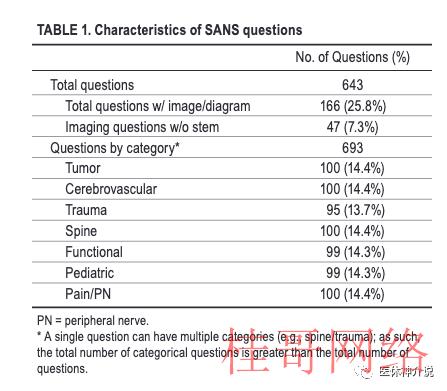
神经外科医师协会 (CNS) SANS问题集是住院医生准备书面考试的主要方式之一,研究者从当选择了643个问题,以评估ChatGPT的能力。因ChatGPT是一个NLP(自然语言处理)模型,允许对一样的输入自动生成不限数量的答案,因此每一个问题会尝试发问三次,以提高获得正确答案的几率。
值得注意的是, 研究版本的ChatGPT不接受图象情势的输入,因此研究者需要输入问题题干,而问题触及的图、表则没法提供给ChatGPT。
研究者统计了以下几个结果:
原始(第一次发问)的总分;
经过三次发问的总分;
去掉包括图表的问题以后的原始总分和三次发问总分。
为了进行分析,这643个问题分别由两名住院医师和四名对神经外科感兴趣的医学生全部作答,以建立公道的基准参数。
这些问题分成了若干大类,每一个分类的平均表现是从SANS网站搜集的,该网站统计了首次答题用户的平均正确率。
研究结果:
643个问题中包括了166个触及图表的问题,ChatGPT谢绝了其中25个问题(3.9%)。
在第一次发问中,ChatGPT正确回答了329个问题(53.2%)。排除包括图象或图表的166个问题后,ChatGPT的正确率稍微提升至54.9%。
在三次发问中,ChatGPT的正确率进一步提高到58.7%,在此基础上排除带有图象或图表的问题后,ChatGPT正确回答了 60.2%的问题。
虽然ChatGPT的表现优于四名医学生(26.3%),并且与用作比较的两名活跃的住院医生(61.5%)相近,但该研究版本的ChatGPT仍低于SANS题库用户的平均水平(69.3%)。
不过,AI模型 在“功能”、“儿科”和“疼痛/外周神经”种别中的正确率优于住院医生,并接近SANS用户的平均水平(在最后一个分类“疼痛/外周神经”中乃至超过了平均水平)。研究者认为这可能反应了正在进行神经外科学习的医生在这些种别中的知识储备相对较差。
研究还指出,与其他种别相比,ChatGPT 在“脊柱”种别上的表现差很多,虽然这类关系还没有得到很好的解释,但这一结果可能与脊柱领域的大量公然信息有关,致使ChatGPT的训练集充斥了更多毛病的信息,也可能由于脊柱相关的问题需要更多参照问题触及的图表才能正确作答。
虽然目前存在局限性,但医生应当了解像ChatGPT这样的技术,由于它们确切显示出增强临床实践的巨大潜力——特别是在三个关键领域。患者的风险辨认、手术计划、手术进程的解释、患者分类和研究是ChatGPT可能支持的神经外科的所有方面。ChatGPT可用于神经外科培训,以帮助制定稳健的、按部就班的手术计划;解释复杂的神经病理学疾病;或告知术前或术后手术计划。虽然现在斟酌将ChatGPT带得手术室可能为时过早,但ChatGPT的进一步发展可能对神经外科培训和增强教育模式非常有用。从患者的角度来看,ChatGPT可用于通过快速回答挥之不去或最后一刻的问题,和为行将到来的约会提供提示、提供术前和术后指点和监测患者症状来帮助患者与他们的医疗团队互动。ChatGPT的对话性质可以帮助告知患者他们的状态,同时也为有效的远程医疗咨询创造机会。在研究领域,ChatGPT可以通过分析大量神经外科数据并提取相关信息来协助创建文献综述。ChatGPT可以在数据中找到模式和相关性,从而对神经外科趋势有新的理解。例如,使用AI系统可以快速肯定选定患者的人口统计数据与脊柱手术后 30 天并发症之间的相关性。ChatGPT还可用于通过挑选患者的资历标准来招募临床实验,同时还可以快速回答有关临床实验规则和条例的问题。未来的计划:ChatGPT 、需要通过医生笔记、图象和手术记录进行数年的培训,然后才能可靠地用于临床环境。未来可能会看到ChatGPT改良外科医生和手术室工作人员之间的沟通,提供术中患者监控,或快速检测成像结果。目前的努力已在尝试将ChatGPT整合到电子健康记录中,创建一个工作流程,让医生可以花更多的时间与病人在一起。ChatGPT已展现了大量的临床利用,神经外科医生应当努力适当地利用人工智能的好处。凭仗更高的精度和效力,我们可以期待ChatGPT在神经外科及其他领域发挥更大的作用,以供未来几代人使用。最新发表在JAMA Internal Medicine上一项比较ChatGPT与执业医生在有关健康问题回答的研究结果表述为“ChatGPT在健康问答中某些方面比医生更出色”。
那末,将来经过充分医学训练的、专业的“人工智能医生”,与人类医生相比会是一种甚么样的景象呢?我们可以大胆,但公道地预期,全球所有医生绑在一起也不及经过充分医学训练的“人工智能医生”的一个脚趾甲。最新的研究怎样说?
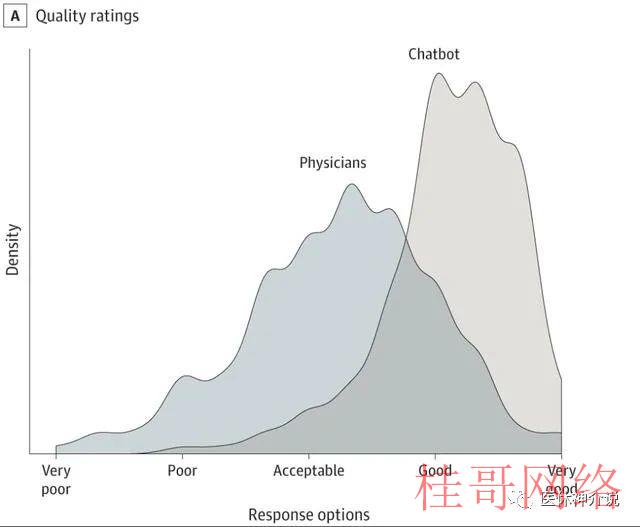
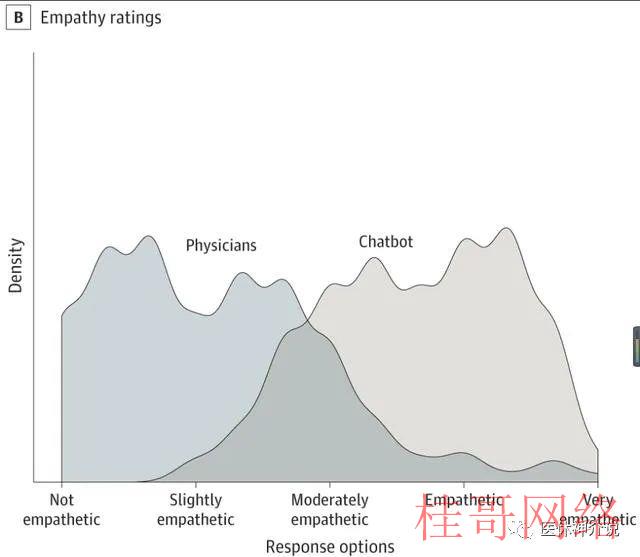
美国加州大学圣地亚哥分校的研究人员从大型在线社交媒体问答网站Reddit有关医学问答的“AskDocs”子论坛上随机抽取了2022年10月期间195个由执业医生做出回答的医学问题,在2022年12月22日和23日提交给ChatGPT生成回答。然后,由3名在儿科、老年医学、内科、肿瘤学、沾染病和预防医学领域持有执业证的专家团队对最初的问题、医生的回答和ChatGPT的回答进行了审查、评分。审查是专家成员在不知道哪些回答是由医生,哪些回答是由ChatGPT提供的情况下的盲评。评估者被要求在做出评估之前浏览完全的发问和两个回答。然后,被要求给出“哪一个回答更好”的答案;再然后评估者使用一个叫做李克特量表的专业工具对两个回答在“提供的信息质量(分为非常差、差、可接受、好或非常好)”和“提供的移情或对病人关心体贴度(分为不移情、轻微移情、中度移情、移情和非常移情)”评估。最后,评估结果被评定为1至5级,评分越高代表更高的回答质量或同理心。01-ChatGPT的回答篇幅更长;
患者的问题平均文字长度为180个字节;医生回答的平均文字长度唯一52个字节,显著短于ChatGPT的211个字节。02-ChatGPT的回答质量显著优于医生;
在专家团给出的585次评估中,78.6%的评估更喜欢ChatGPT的回答的回答。评估者认为ChatGPT的回答质量明显高于医生,ChatGPT的回答整体上优于“好”,平均评分高达4.13;而医生的回答被整体评估为略优于“可接受”,平均评分为3.26;两相比较,医生的回答整体得分比ChatGPT低了21%。医生的回答中有高达27.2%被评估为低于可接受的质量(得分< 3);而ChatGPT回答的这一比例仅有2.6%;这相当于ChatGPT对医生构成了高达10.6倍的碾压性优势。ChatGPT的回答质量被评为好或非常好的比例高达高于78.5%,对应的医生这一比例唯一22.1;这相当于ChatGPT对医生构成了3.6倍的优势。ChatGPT的回答还认为更具有同理心,平均评分为3.65;而医生的平均评分唯一2.15。整体上医生的得分比ChatGPT低了41%,这相当于医生回答仅略微有同理心,而ChatGPT的回答整体属于有同理心。另外,医生的回答被评定为仅具有轻微同理心(<3)比例达80.5%;大大高于ChatGPT的14.9%;这相当于ChatGPT相对医生取得了5.4倍的巨大优势。ChatGPT的回答被评为具有同理心或非常具有同理心的比例为45.1%,远远高于医生的4.6%;这相当于ChatGPT在同情心方面相对医生获得了9.8倍的优势。透过以上的对照,不言而喻,即便ChatGPT不过是初出茅庐的通用专家,在医学问答方面对经过量年医学教育和训练的医学博士(美国的临床医生都是博士)+多年临床实践经验积累的临床专家就能够轻而易举产生碾压性优势。让人稍感意外的是,ChatGPT更大的优势竟然是在同情心方面,而不是回答的医学专业性和质量方面。这样看来,等到真实的经过充分训练的“专业人工智能医生”问世,对人类医生产生我前面预期的“全球所有医生绑在一起也不及经过充分医学训练的“人工智能医生”的一个小脚趾甲”的无以言表的优势,绝非妄语。关注医休神介说,有趣,有料,有得聊~
【免责声明】
本公众号注明原创的内容权利属于本服务或本服务权利人所有,未经本服务或本服务权利人授权,任何人不得擅自使用(包括但不限于复制、传播、展现、镜像、上载、下载、转载、摘编等)也许可他人使用上述知识产权的。已本服务或本服务权利人授权使用作品的,应在授权范围内使用,并注明作者来源。否则,将依法追究其法律责任。本公众号标注为转载的部份内容来自互联网,版权归原作者所有,仅供学习参考之用,制止用于商业用处,如无意中侵犯了哪一个媒体、公司 、企业或个人等的知识产权,请联系删除。
欢迎加医休哥微信,请备注单位+姓名

加入“医休神介说”知识星球,超1500份资料和和会员专属社群

tk账号购买:https://www.tiktokfensi.com/