
本参考指南当前包括的内容:
1、GPT⑷ API 要求/响应模式
2、Python示例:OpenAI Python 库和LangChain
3、为何使用GPT⑷ API
Tips:
LangChain:是一个用于构建基于大型语言模型(LLM)的利用程序的库
Postman 中要求 GPT⑷ API
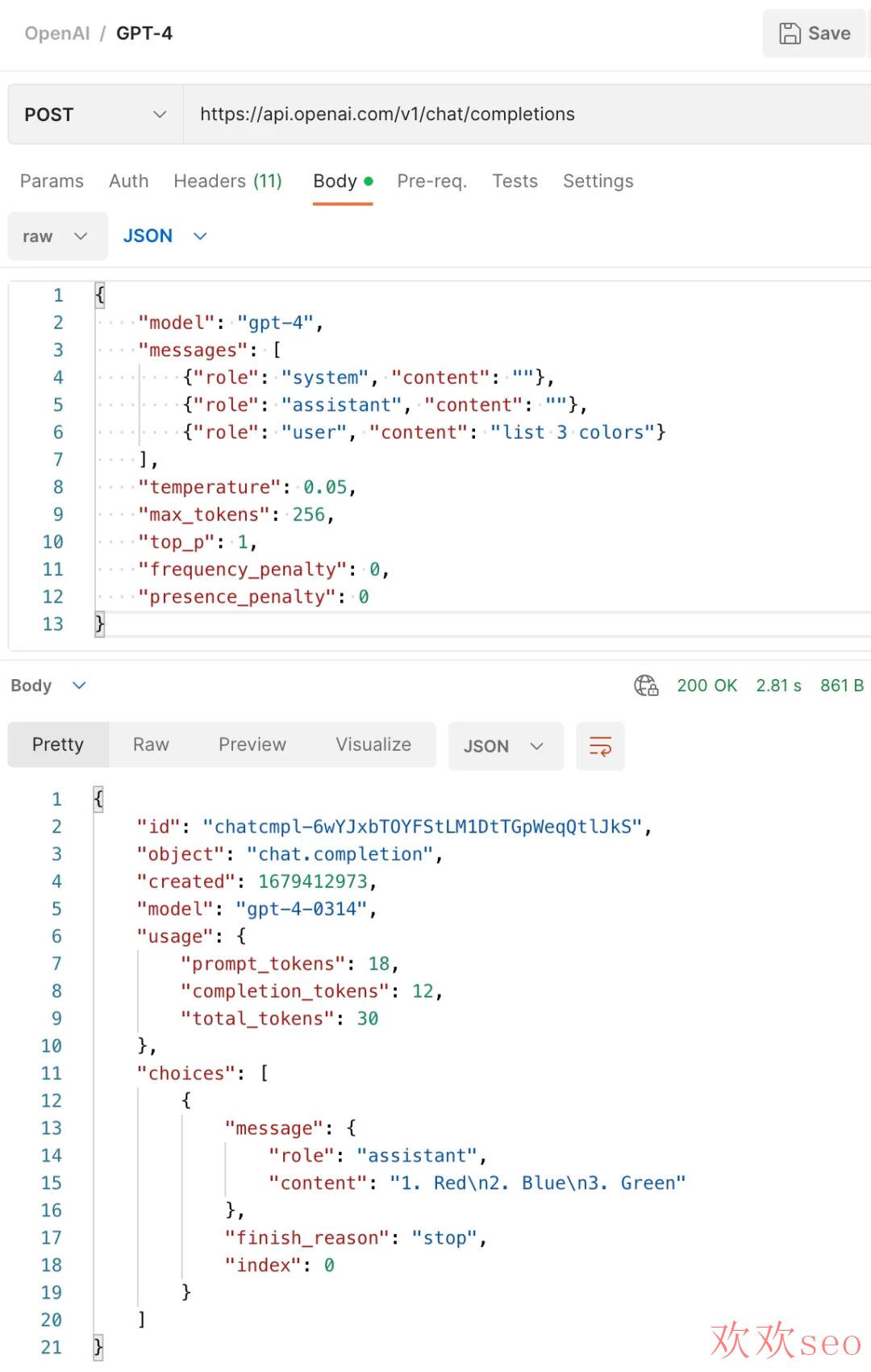
GPT⑷ 的 API 要求
POST https://api.openai.com/v1/chat/completionsContent-Type: application/jsonAuthorization: Bearer YOUR_OPENAI_API_KEY{ "model": "gpt⑷", "messages": [ {"role": "system", "content": "Set the behavior"}, {"role": "assistant", "content": "Provide examples"}, {"role": "user", "content": "Set the instructions"} ], "temperature": 0.05, "max_tokens": 256, "top_p": 1, "frequency_penalty": 0, "presence_penalty": 0}
model: 正在使用哪一个版本 (例如:"gpt⑷")messages:
- system:系统消息有助于设置助手的行动。在上面的例子中,助手被唆使 “你是一个得力的助手”。
- assistant:助手消息有助于存储先前的回复。这是为了延续对话,提供会话的上下文。
- user:用户消息有助于指点助手。就是用户说的话,向助手提的问题。
temperature:采样温度,值介于 0 到 2 之间。值越高,输出就越随机。例如你希望对同一个问题,模型每次的回复都能有较大的差异,就能够设置为一个较高的值。该参数与 top_p 通常只建议修改其中一个。
max_tokens:官方翻译过来是。完成进程中要生成的最大令牌数,提示加上max_tokens的标记计数不能超过模型的上下文长度。大多数型号的上下文长度为2048个令牌(除支持4096的最新型号)。max_tokens是OpenAI GPT语言模型中的一个参数,用于指定生成文本时最多可使用的标记(tokens)数。标记是将文本分割为单独的单词或符号的基本单位。因此,max_tokens参数限制了生成的文本长度。在使用OpenAI GPT模型生成文本时,可以设置max_tokens参数以控制生成的文本长度。例如,如果将max_tokens设置为50,则生成的文本将不会超过50个标记,即50个单词或符号。如果生成的文本到达了max_tokens的限制,模型将停止生成更多的文本。总的来讲:max_tokens就是AI回复的最大单词数量。top_p:一种替换温度采样的方法,称为核采样。模型只斟酌具有 top_p 几率质量的 token 的结果。例如设为 0.1 模型就只斟酌构成前 10% 几率质量的 token。该参数与 temperature 通常只建议修改其中一个。
frequency_penalty:值介于 ⑵.0 到 2.0 之间。正值会根据新生成 token 在文本中的频率对其进行惩罚,从而下降模型逐字重复同一行的可能性。presence_penalty:值介于 ⑵.0 到 2.0 之间。正值会根据会不会已出现在文本中来惩罚新生成的 token,从而鼓励模型生成新的内容,避免出现大段重复的文本。GPT⑷ API Response
{ "id": "chatcmpl⑹viHI5cWjA8QWbeeRtZFBnYMl1EKV", "object": "chat.completion", "created": 1680192762, "model": "gpt⑷-0314", "usage": { "prompt_tokens": 21, "completion_tokens": 5, "total_tokens": 26 }, "choices": [ { "message": { "role": "assistant", "content": "GPT⑷ response returned here" }, "finish_reason": "stop", "index": 0 } ]}
model:模型,暂时的通知,OpenAI将支持到6月14日。 prompt_tokens:要求参数里面含有的token数,每 750 个单词定价为0.03 美元的token数量(1000tokens) completion_tokens:返回结果含有的token数,每 750 个单词定价为0.06 美元的token数量(1000tokens) message:角色(即“助理”)和内容(实际响应文本)。 finish_reason:告知我们为何助手停止生成响应。在这类情况下,它停止是由于它到达了一个自然停止点(“停止”)。有效值为stop、length、content_filter 或 null。 index:这只是一个用于跟踪响应的数字(0 表示它是第一个响应)。Python 示例
虽然可使用上面信息向 GPT⑷ API 发出 HTTPS 要求,但建议使用官方 OpenAI 库或更进一步使用 LLM 抽象层,如 LangChain。地址:https://colab.research.google.com/gist/IvanCampos/c3f70e58efdf012a6422f2444dc3c261/langchain-gpt⑷.ipynb#scrollTo=TjnIGuQfNvzt用于 OpenAI Python 库和 LangChain 的 Jupyter Notebook

1、安装openai的包,它提供了与 OpenAI API 通讯的工具。
2、
1)导入openai,使其在项目中可使用;
2)设置访问OpenAI API 所需的密钥。
将您的实际密钥替换“YOUR_OPENAI_API_KEY”。
3)设定模型,然后发送一个要求,让他用7个词解释为何人工智能是未来。
4)打印响应结果
import openaiopenai.api_key = "YOUR_OPENAI_API_KEY"completion = openai.ChatCompletion.create( model="gpt⑷", messages=[{"role": "user", "content": "in 7 words, explain why artificial intelligence is the future"}] )print(completion.choices[0].message.content)

LangChain 说明
LangChain 是一种旨在抽象化和简化大型语言模型 (LLM) 工作的工具。它可以用于各种目的,例如:创建聊天机器人、回答问题或总结文本。LangChain 背后的主要思想是您可以将区别的部份连接在一起,以使用这些 LLM 制作更复杂和高级的利用程序。
LangChain notebook cells如果独立运行,需要pip安装导入openai
!pip install langchain:安装“langchain”的包,它提供了与 LLM 通讯的工具。from ... import ...: 这些行从“langchain”包中导入特定的函数和类(或工具),因此它们可以在脚本中使用。os.environ['OPENAI_API_KEY'] = 'YOUR_OPENAI_API_KEY':此行设置访问OpenAI API 所需的密钥。您将用您的实际密钥替换“YOUR_OPENAI_API_KEY”。chat = ChatOpenAI(...):此行创建具有特定设置(如温度)的 GPT⑷ API 实例。chat([...]):这些行显示了如何向 API 发送消息和接收响应。template = "You are a helpful assistant...: 这部份设置一个提示模板来定义要求的行动。在这类情况下,它告知 GPT⑷ 它是一个有用的翻译器。system_message_prompt = ...:这行创建一个 SystemMessagePromptTemplate,它将用于使用之前定义的模板设置助手的行动。human_message_prompt = ...这行创建一个 HumanMessagePromptTemplate,它将用于格式化用户发送的消息。chat_prompt = ...:这即将系统和人工消息提示组合到一个 ChatPromptTemplate 中。chat(chat_prompt.format_prompt(...)):这行使用 ChatPromptTemplate 向 API 发送一条消息。chain = LLMChain(llm=chat, prompt=chat_prompt):这行创建了一个 LLMChain 对象,它简化了与 LLM 的交互。chain.run(...):这行使用 LLMChain 对象向 GPT⑷ API 发送一条消息。
为何选择 GPT⑷?
一个最明显的好处就是 GPT⑷ API 接受上下文长度为8,192 个token(12.5 页文本)的要求——这是GPT⑶.5 上下文长度的2 倍。另外,与之前的模型相比,GPT⑷ 在推理和完成响应的简洁性方面表现出色。


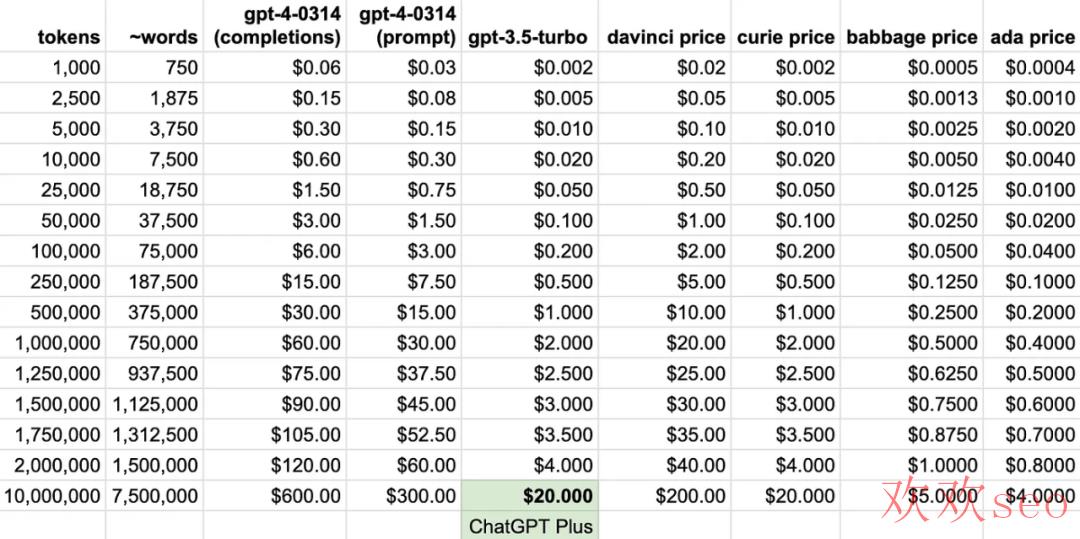
价钱
在决定会不会使用 GPT⑷ API 时最困难的选择是定价——由于 GPT⑷ 定价的工作原理以下:
- prompt:每 750 个单词 0.03 美元(1k tokens)
- completions:每 750 个单词 0.06 美元(1k tokens)
GPT⑷ API 比 ChatGPT 的默许模型 gpt⑶.5-turbo贵 14⑵9 倍。
未来的改进
在行将发布的GPT⑷API中,它将是多模式的。在这类情况下,“多模型”指的是API不但接受文本,还接受图象的能力。目前,图象输入仅由Be My Eyes进行测试。还有一个32768上下文长度模型(50页文本)目前是预览版本,与gpt⑷–0314相比,上下文长度增加了4倍。但是,这将是8192上下文长度GPT⑷模型的两倍本钱。虽然在GPT⑶ API模型(davinci、curie、babbage和ada)中可以进行微调,但预计在未来的版本中会为GPT⑷ API提供微调。目前的培训数据仅截至2021 9月。预计在未来的版本中也会增加这一点。当通过ChatGPT-Plus使用GPT⑷时,截至今天:“GPT⑷目前的上限为每3小时25条消息。随着我们根据需求进行调剂,预计上限会大大下降。”随着上限的下降,预计GPT⑷ API的直接使用量会增加。
https://www.bemyeyes.com/若需获得ChatGPT 研究框架报告,请关注PikeTalk公众号:PikeTalk,并回复:框架报告,便可取得PDF版报告全文。若需获得GPT⑷ 技术报告,请关注PikeTalk公众号:PikeTalk,并回复:技术报告,便可取得PDF版报告全文。
tk账号购买:https://www.tiktokfensi.com/




